Back in October 2014, John Reilly, a Subject Matter Expert and Distinguished Fellow with the TM Forum published a piece on LinkedIn[1] about the future of the Business Process Framework (more commonly known as the enhanced Telecom Operations Map (eTOM)) that is published by the TM Forum. His proposals are based around a domain based structure making the eTOM more closely aligned with the structure of the Information Framework (aka SID) and the Technical Application Framework (aka TAM). This re-structuring has addressed some of the issues that are apparent with the eTOM and its relationship with the other frameworks that make up the Frameworx document set.
The evolution of the Business Process Framework
But firstly a bit of history about the development of the eTOM, its previous incarnation the TOM and the SID.
The Telecom Operations Map (TOM), itself based upon the ITU-T Telecommunications Management Network (TMN) model and earlier work done by the TMForum, was proposed in the late 1990s and looked at defining the key processes required by a Telecommunications Company to manage its operations.
 Telecom Operations Map ©TM Forum
Telecom Operations Map ©TM Forum
As can be seen, the TOM copied the management layers defined in the TMN standard. The document (GB910) which set out the TOM also described end to end processes based upon Fulfilment, Assurance and Billing which could be overlaid onto the TOM model.
 TOM ‘FAB’ End-to-End Process Breakdown ©TM Forum
TOM ‘FAB’ End-to-End Process Breakdown ©TM Forum
The structure of the TOM model not just implied, but made explicit, how process flows ‘worked’ from a Customer placing an order to the Services being planned and the Network being configured to deliver that particular order. This became the basis of how process flows using the TOM were modelled.
The TOM evolved into the eTOM over the next couple of years, becoming a total enterprise process framework, encompassing all the processes needed by an organisation. The basic structure of the framework, vertical process groupings and the associated end-to-end flows, was not altered; though more were added. This caused some confusion, particularly with the introduction of the Supplier/Partner processes as many looking at the model, and familiar with the end-to-end process flows that had been defined in the TOM, assumed that processes needed to flow though all management layers from Customer to Supplier/Partner.
 eTOM v1 ©TM Forum
eTOM v1 ©TM Forum
The eTOM continued to evolve with much of its development focused upon the decomposition and definition of lower level processes but the overall structure of the framework changed relatively little over the next decade.
 eTOM Level 0 Processes, Release 8 © TMForum
eTOM Level 0 Processes, Release 8 © TMForum
Development of the SID
The principles of what was to become the Shared Information/Data Model (SID) were first proposed in 1999. Initially two separate development strands: The Shared Integration Map (SIM) and the Shared Information/Data Model: ran together within the TMForum. The SIM[2] proposed a number of different management domains and defined, to some, degree how they were related to the TOM processes.
 SIM Management Domains © TMForum
SIM Management Domains © TMForum
 Primary Mapping Between the Management Domain Concept and the TOM ©TMForum
Primary Mapping Between the Management Domain Concept and the TOM ©TMForum
The eTOM and SID continued to be developed separately, for a number of years, as each fulfilled a different requirement for the TM Forum members and their respective roles within, what was, the NGOSS lifecycle. A mapping between the SID ABEs and the eTOM level 2 processes[3] allowed process modellers to more easily to use the SID to enrich their process flows while using the same constructs as system developers and integrators.
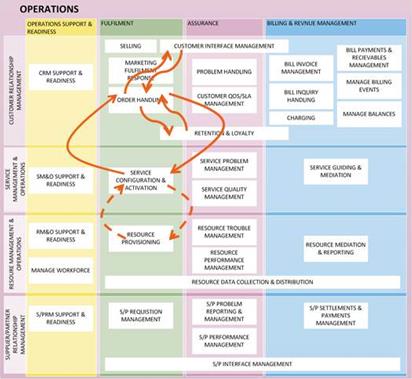
The issues with structure of the eTOM remain and recent developments, as discussed in John Reilly’s blog, have been more focused upon the addressing alignment between the SID and eTOM. These changes haven’t removed one of the key advantages of the eTOM, in that is very easy to construct initial process flows using the model; as illustrated in the figure below.
 Initial Process Flow Constructed Using the eTOM
Initial Process Flow Constructed Using the eTOM
While the recent changes to the eTOM have been a good way forward but they do not address some of the fundamental issues of the structure of the eTOM, for example:
- How Customer and Supplier/Partner interact with the vertical and horizontal processes groupings.
- The relationship between vertical process flows and horizontal functional groupings
- The relationship between the eTOM and the SID.
- How Enterprise Management works with the Operations and SIP Process Areas.
Is there another way of viewing a process framework?
When ITIL® was refreshed in 2007 it introduced a fundamental change in how the framework was visualised and published a view of the framework which illustrated the Service Management Lifecycle and the relationship of the five key process areas.
 ITIL v3 Service Management Lifecycle
ITIL v3 Service Management Lifecycle
Similarly COBIT and TOGAF have lifecycle models which define the relationship between process areas from which process flows can be derived.
So is there are better way of laying out the eTOM?
Does the structure of the eTOM need to change, so member organisations, particularly new members and other industries, immediately understand how the eTOM can benefit them to meet the challenges they are facing not just now, but in the future? It is clear that what has been developed so far should not be wholly discarded; this paper is concerned with how the L0 and L1 process groupings, and possibly the L2 processes, are presented and what makes up those groupings. The issues with the eTOM structure that were described earlier can be, for the most part, condensed to one key issue – there is no clear process lifecycle throughout the framework; the process and external relationships implied by the layout of the eTOM can make the framework difficult to understand initially. And where lifecycles have been defined, e.g. Infrastructure Lifecycle Management and Product Lifecycle Management, the relationship between them and other areas of the eTOM is poorly described.
So what is proposed is that level 0 and level 1 groupings and relationship be redefined. Key to these changes to the eTOM structure would be the definition of the various lifecycles (i.e. Product Lifecycle, Infrastructure Lifecycle, Customer Lifecycle, Supply Chain Lifecycle etc) that exist within the framework as well as the inter-lifecycles (for example Fulfilment, Assurance and Billing with the Customer Lifecycle.) Defining the lifecycles would provide an opportunity for closer alignment between the level 1 process groupings (which would themselves become lifecycle groupings in this proposed new framework structure) and the relevant SID domains. Once these have been described, then the relationships between the different lifecycles can be established and the framework’s new structure derived. This would allow the relationships between the lifecycles and the internal and external stakeholders to be more clearly illustrated.
Caution should be taken, in that any re-design of the structure of the framework must maintain one of the principle benefits of the current layout; the ease by which initial process flow can be constructed.
This is not a simple task, but there is an opportunity to look at the eTOM and see how it could be redesigned to support the digital transformation that is affecting all industries.
[1] https://www.linkedin.com/pulse/20141029152421-7101265-the-future-business-process-framework-etom?trk=object-title
[2] GB914 System Integration Map
[3] GB922 Concepts and Principles